Interleaved Scene Graph Team



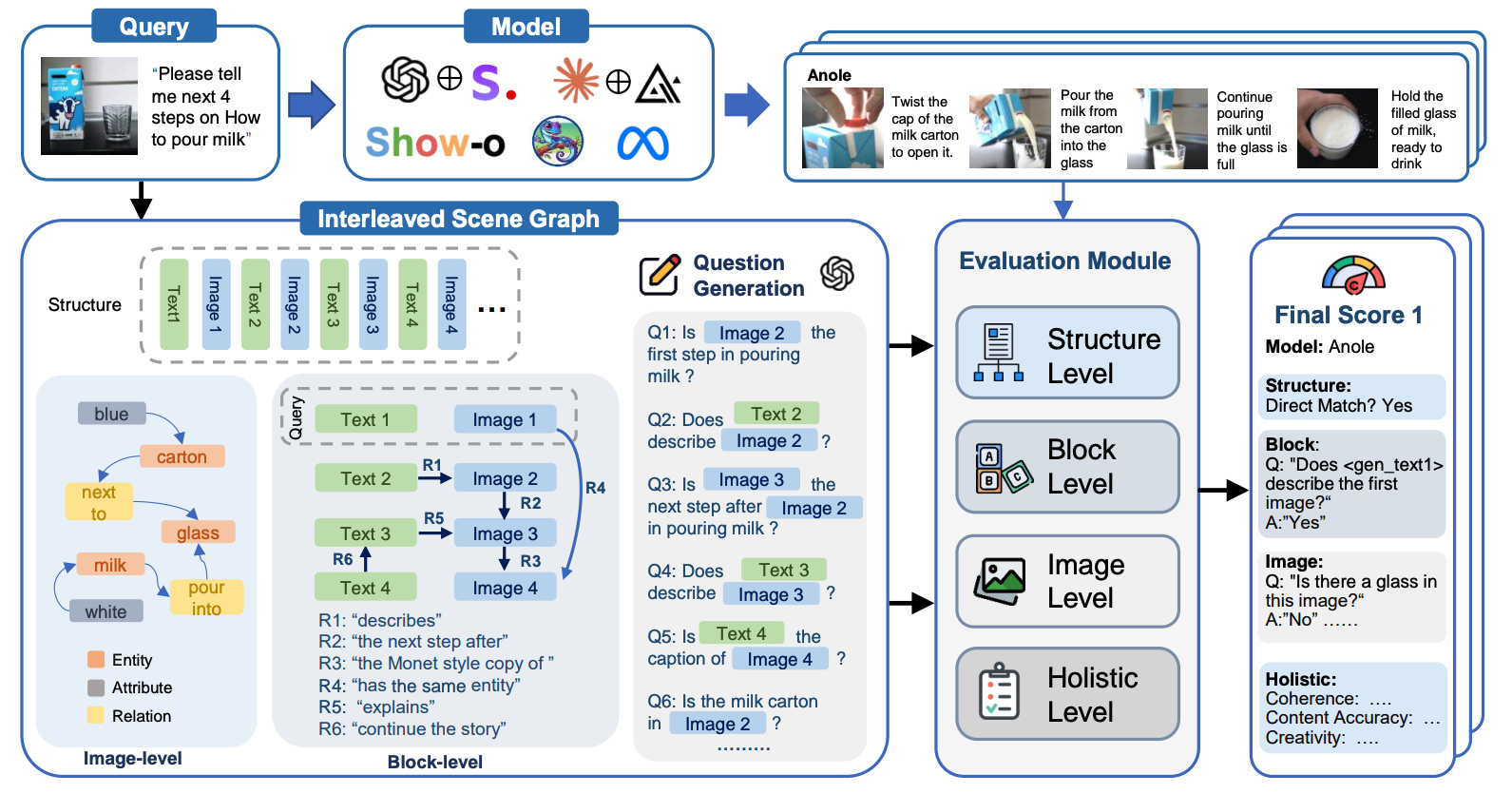 We introduce Interleaved Scene Graph (ISG), a multi-granular, automatic evaluation framework for interleaved text-and-image generation,
which assesses responses across four levels, detailed as follows:
We introduce Interleaved Scene Graph (ISG), a multi-granular, automatic evaluation framework for interleaved text-and-image generation,
which assesses responses across four levels, detailed as follows:
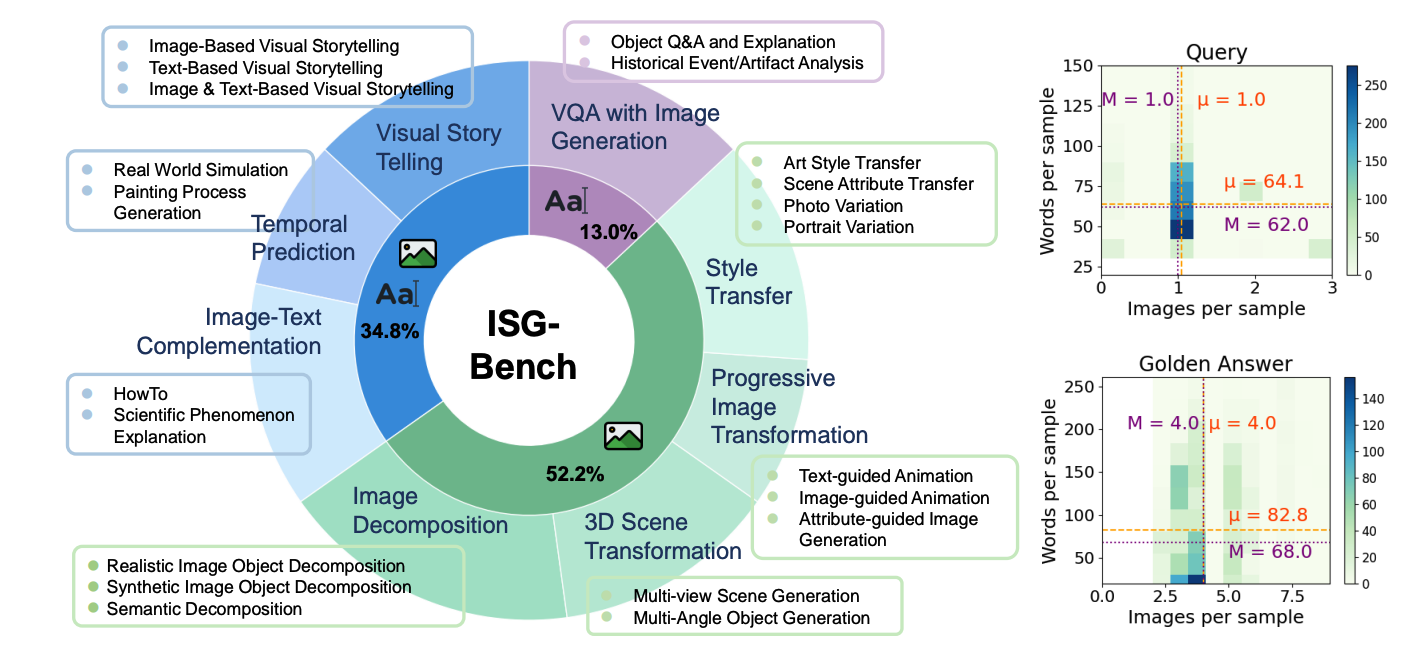
 ISG-BENCH is our benchmark for interleaved text-and-image generation,
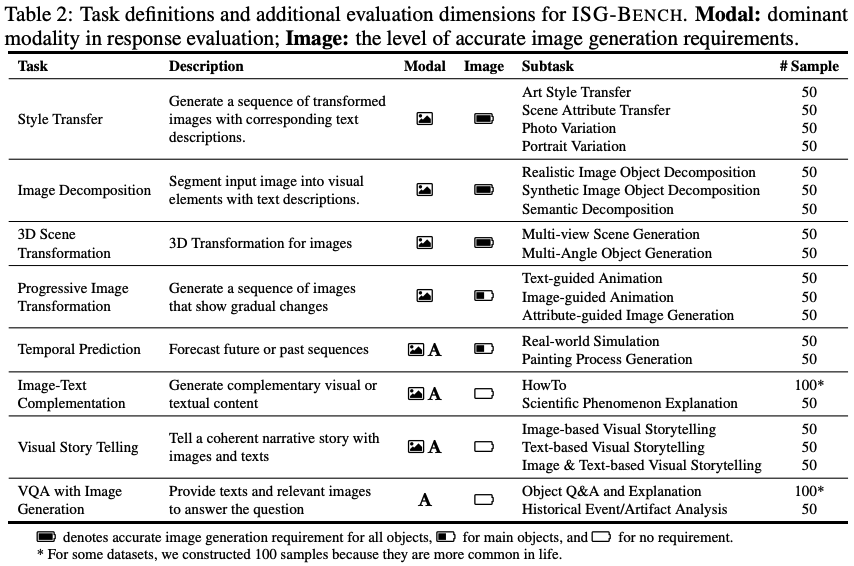
featuring 1,150 samples across 21 subtasks in 8 scenarios. It evaluates multimodal understanding, generation,
and instruction-following. All queries are vision-language dependent, with golden reference answers.
Samples were carefully curated using cross-validation and similarity filtering.
ISG-BENCH is our benchmark for interleaved text-and-image generation,
featuring 1,150 samples across 21 subtasks in 8 scenarios. It evaluates multimodal understanding, generation,
and instruction-following. All queries are vision-language dependent, with golden reference answers.
Samples were carefully curated using cross-validation and similarity filtering.
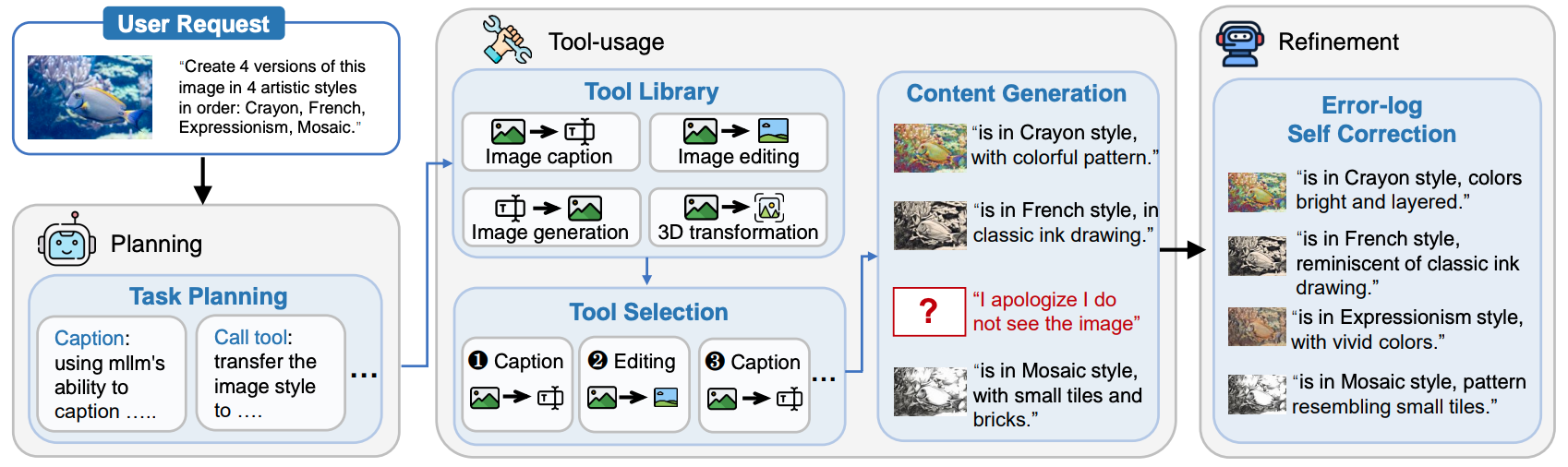 ISG-AGENT, our pioneering framework for interleaved text-and-image generation,
addresses the challenges faced by unified generation models through a three-component system:
(1) Planning, which interprets multimodal queries and generates tool usage plans;
(2) Tool-usage, which executes appropriate tools with detailed logs for text and image generation; and
(3) Refinement, which reviews and enhances generated content by addressing errors and improving coherence.
This "Plan-Execute-Refine" pipeline ensures outputs that closely adhere to user instructions while autonomously handling diverse tasks,
leveraging multimodal language models and specialized tools to create cohesive, text-image-aligned content that goes beyond discrete blocks.
ISG-AGENT, our pioneering framework for interleaved text-and-image generation,
addresses the challenges faced by unified generation models through a three-component system:
(1) Planning, which interprets multimodal queries and generates tool usage plans;
(2) Tool-usage, which executes appropriate tools with detailed logs for text and image generation; and
(3) Refinement, which reviews and enhances generated content by addressing errors and improving coherence.
This "Plan-Execute-Refine" pipeline ensures outputs that closely adhere to user instructions while autonomously handling diverse tasks,
leveraging multimodal language models and specialized tools to create cohesive, text-image-aligned content that goes beyond discrete blocks.
| Eval Level | Eval Task | Metric | Size | Avg. | Image | Image-Language | Language | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Style | Prog. | 3D | Dec. | I-T C. | Temp. | VST | VQA | |||||
| Structure | Direct Match | Accuracy | 1,150 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Block | Q-Gen | Acc+BS | 1,150 | 0.967 | 0.955 | 0.988 | 0.890 | 0.970 | 0.993 | 0.980 | 0.980 | 0.980 |
| VQA Score VQA YesNo |
Pearson | 1,092 | 0.718 | 0.482 | 0.529 | 0.581 | 0.850 | 0.778 | 0.816 | 0.873 | 0.835 | |
| 0.446 | 0.169 | 0.386 | 0.528 | 0.382 | 0.555 | 0.388 | 0.634 | 0.529 | ||||
| Image | Q-Gen | Acc+BS | 1,150 | 0.811 | 0.949 | 0.761 | 0.553 | 0.925 | 0.884 | 0.817 | 0.792 | - |
| VQA YesNo | Accuracy | 4,871 | 0.907 | 0.851 | 0.873 | 0.863 | 0.937 | 0.968 | 0.921 | 0.934 | - | |
| Holistic | w. GT | Agreement | 260 | 0.730 | 0.720 | 0.620 | 0.660 | 0.600 | 0.950 | 0.750 | 0.640 | 0.900 |
| w.o. GT | 0.537 | 0.600 | 0.460 | 0.450 | 0.400 | 0.900 | 0.600 | 0.370 | 0.800 | |||
 We evaluate 10 frameworks capable of generating interleaved text-and-image
content, four recently released unified models, Show-o, Anole, Minigpt-5, CoMM-Minigpt-5 , SEED-LLaMA as well as two compositional settings, using Gemini-1.5-Pro (GeminiTeam, 2023)
and Claude-3.5-Sonnet as a multimodal preceptor2
and SD3 as its generator, with SD2.1 for ablation study. For our ISG-AGENT, we
use GPT-4o for planning and verification agent, and use Claude-3.5-Sonnet for tool selector, with
SD3 as image generator and multiple tools (UltraEdit, DynamiCrafter, SV3D, DreamMover).
We evaluate 10 frameworks capable of generating interleaved text-and-image
content, four recently released unified models, Show-o, Anole, Minigpt-5, CoMM-Minigpt-5 , SEED-LLaMA as well as two compositional settings, using Gemini-1.5-Pro (GeminiTeam, 2023)
and Claude-3.5-Sonnet as a multimodal preceptor2
and SD3 as its generator, with SD2.1 for ablation study. For our ISG-AGENT, we
use GPT-4o for planning and verification agent, and use Claude-3.5-Sonnet for tool selector, with
SD3 as image generator and multiple tools (UltraEdit, DynamiCrafter, SV3D, DreamMover).
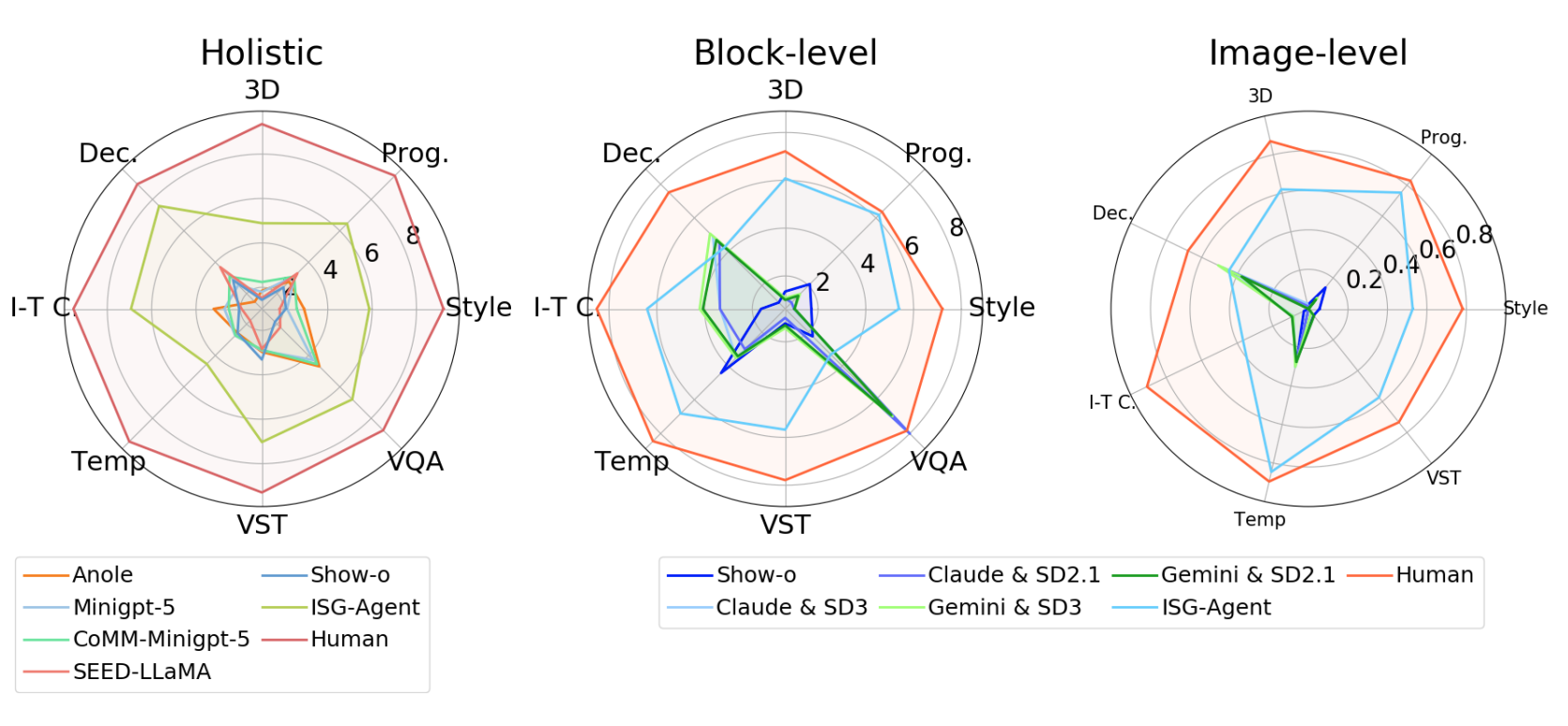
Each module within ISG aligns well with human annotation. For structure, ISG exhibits consistent excellence across all tasks, indicating robust potential for capturing structural requirements in interleaved generation instructions. In both Q-Gen and VQA modules, ISG successfully extracts fine-grained requirements with high fidelity to ground truth. For VQA module, the scoring approach consistently outperforms the “Yes-or-No” method, suggesting that more nuanced judgments align better with human evaluations. Vision-guided tasks consistently underperform compared to other tasks, with a noticeable decline in both Q-Gen and VQA modules, underscoring the challenges in automatically evaluating fine-grained aspects of interleaved text-and- image generation. In holistic evaluation, leveraging a golden answer significantly outperforms the zero-shot judging setting of MLLMs, especially in vision-guided tasks, yielding an average 20% improvement in human agreement.
We evaluate our ISG under two conditions: vision input and few-shot examples, for a more comprehensive study. Multimodal input varies in block-level and image-level question generation, with a slight enhance- ment in image-level question generation. In addition, few-shot in-context learning provides dramatic enhancement on both tasks, improving performance by more than 30% in block-level and 10% in image-level tasks, especially in vision-language guided tasks by limiting requirements for the predicted generative content. For language-guided tasks, few-shot learning brings a 70% enhancement in block-level performance, further demonstrating the accurate evaluation framework establishment for this type of creative generation task.
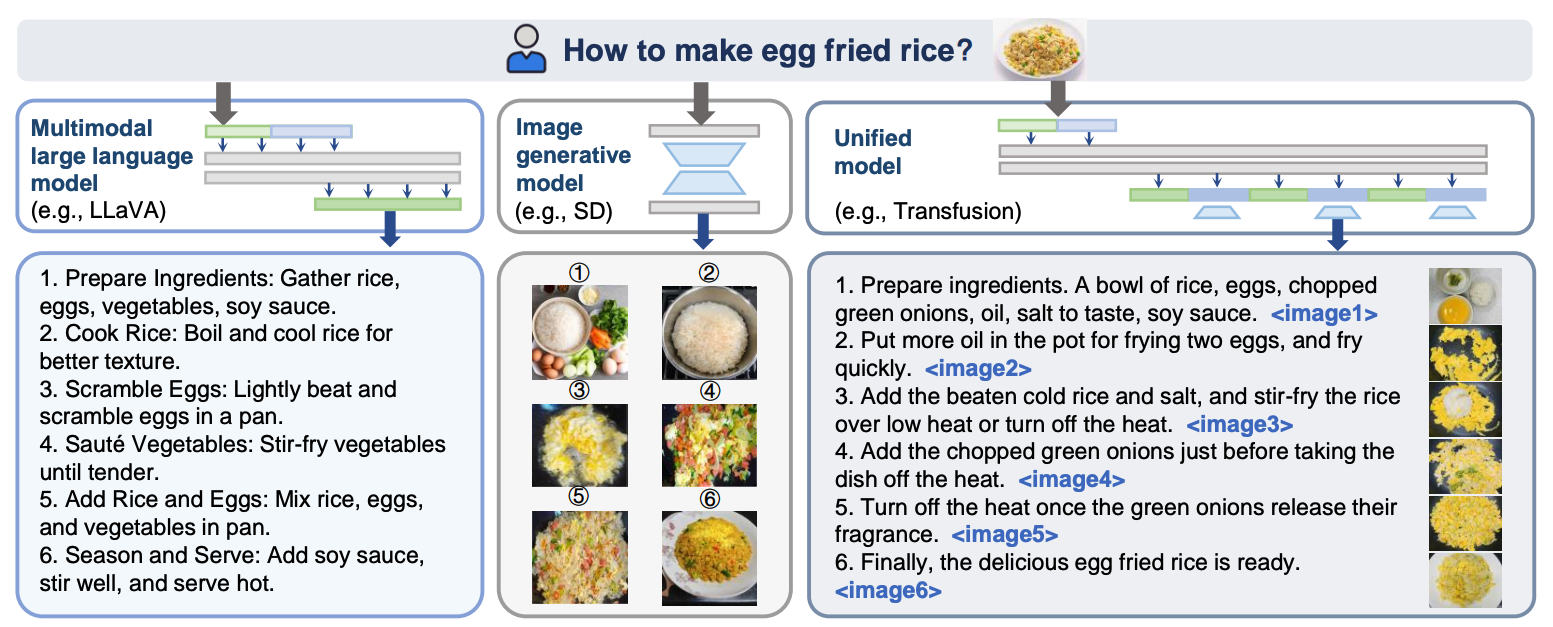
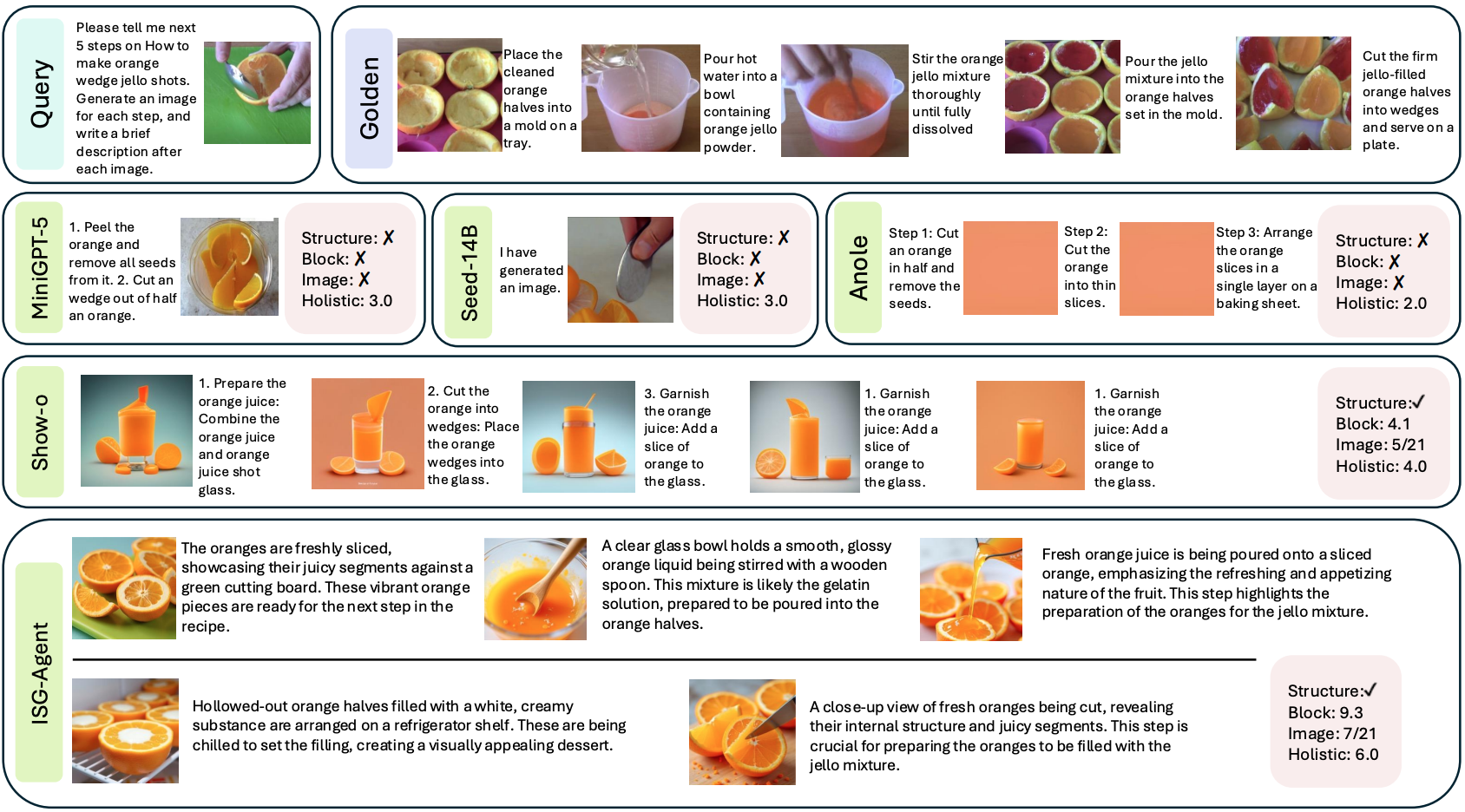
All unified models exhibit significant deficiencies in following instructions to generate interleaved text-and-image content. Many models produced only one to three images, while some failed to generate any images at all. Consequently, these models could not be subjected to block-level and image-level evaluation protocols. In terms of holistic evaluation, the models demonstrated superior capabilities in language-dominant tasks, while notably underperforming in vision-dominant tasks. This disparity further proves the hypothesis that current training datasets for unified models lack sufficient vision-dominant instruction tuning samples, such as those for "Style Transfer" and "Image Decomposition". Notably, Show-o, as one of the first unified autoregressive models, stands out in precise generation structure but falls short in generating high-quality responses due to hallucinations, which generate images related to system prompts instead of user's instructions. Moreover, Anole also shows potential in interleaved generation and achieves state-of-the-art results among other unified models, suggesting the potential efficacy of its advanced architecture.
ISG-Agent strictly follows users' requirements to generate interleaved content, achieving comparative results to human's golden answer in various tasks in both block-level and image-level, especially in vision-dominated tasks like "Style Transfer" and "3D Scene". The state-of-the-art results in "Progressive Transformation" also demonstrate good coherence of the image content, even accommodating to human-collected answers. Although LLM+Diffusion frameworks fall short in accurate instruction-following, they achieve state-of-the-art results in holistic evaluation in some language-dominated tasks, demonstrating their high generation quality of textual information.
Given that these compositional frameworks perceive images and generate images separately, not end to end, they naturally cannot perform these tasks well such as accurate image editing due to their inherent structure. On the other hand, although these unified models have the potential to understand and generate images in an end-to-end manner and announce their capability in vision generative tasks such as "Image Generation" or "Image Editing", they fall short in understanding multimodal queries to generate interleaved content with multiple images. The best unified model Anole fails to understand the output format and deviates from the context of input images, demonstrating their deficiency in generating images in vision in-context learning.
The inconsistency between holistic evaluation results and those at three fine-grained levels reveals a notable limitation in MLLM-as-a-Judge to comprehensively assess responses, even when provided with both the user's instruction and correct golden answer. Specifically, Judge MLLM struggles to evaluate responses according to fine-grained criteria, such as output structure (including image count) and the detailed text-image relationships stipulated in the prompt. Furthermore, our analysis of the results uncovers an inherent bias within MLLM-as-a-Judge, namely "image-quality bias", where higher scores are consistently awarded to responses featuring higher-quality image content, despite these responses potentially violating the user's instructional requirements and judging guidelines. This bias demonstrates that MLLM-as-a-Judge, even provided with a golden answer, still cannot properly perform accurate assessments on interleaved responses that adhere to specified requirements.
The comparative analysis between two image generation models and ablation study on tools consistently demonstrates superior performance across various task levels when employing enhanced components, thereby underscoring the importance of advanced tools in producing more accurate and high-fidelity content. Furthermore, the incorporation of a refinement module significantly contributes to improved text-image alignment, substantially enhancing both block-level and holistic performance, which highlights the potential for optimizing individual components to achieve precise interleaved generation within a compositional framework.
Our results highlight the potential of unified autoregressive model structures like Anole and Show-o, while revealing substantial room for improvement in their instruction following and accurate generation capabilities. This underscores the need for dedicated interleaved datasets, particularly for vision-dominant tasks. Current datasets, limited to unimodal tasks or loosely aligned vision-language pairs, inadequately address the challenges of generating coherent interleaved content. Additionally, existing interleaved datasets are predominantly language-centric, failing to establish robust vision-language dependencies crucial for enhanced multimodal understanding and generation. In this context, our compositional agent, ISG-AGENT, shows promise as a pipeline for synthetic interleaved instruction tuning and vision-centric data, potentially advancing the development of unified generative models.
Although we have carefully built the whole benchmark from scratch with cross-validation and evaluate the reliability of these generative models in the question generation and VQA module, concluding that it's practical to use them as evaluators, the potential trustworthiness problem of LLMs should be noted as they still make mistakes in evaluation. Moreover, due to their inherent structure, their evaluation lacks transparent and interpretable results. Therefore, a future direction lies in reducing the AI models in the evaluation process, like Task Me Anything, to synthetically generate questions paired with answers to evaluate model performance with highest truthfulness and confidence.
In this study, we explore a compositional agent strategy that integrates diverse model modules to generate interleaved multimodal content. Experimental results indicate that further enhancing each sub-module's performance may significantly improve the overall generative capabilities. Consequently, the compositional model not only demonstrates high flexibility and adaptability but also serves as a pivotal component in the advancement of unified models, particularly by functioning as a synthetic data pipeline to facilitate interleaved dataset construction. By leveraging high-quality generated content, this synthetic dataset further augments the generalization capabilities of unified multimodal models. Thus, its application not only contributes to exploring the upper-performance bounds of current models but also provides valuable insights and guidance for the design and optimization of future unified models.
While ISG-BENCH provides a strong foundation for evaluating accurate multimodal interleaved generation, a critical yet underexplored aspect is trustworthiness within these models. However, evaluating trustworthiness for interleaved generation presents several key challenges: (1) Previous research mainly focuses on single-modality generative models (e.g., LLMs), while challenges across text-and-image are not well addressed. (2) Another significant challenge is assessing the robustness of interleaved generation models against adversarial inputs (e.g., jailbreak attacks) or unexpected variations in prompts. These models may produce misleading or harmful outputs when manipulated through subtle alterations in the input text or images. Evaluating a model's resistance to such attacks is particularly difficult in a multimodal setting, as an attack could target just one modality (e.g., a slight change in a word or a pixel) and still cause cascading effects on the overall output.
@article{chen2024interleaved,
title={Interleaved scene graphs for interleaved text-and-image generation assessment},
author={Chen, Dongping and Chen, Ruoxi and Pu, Shu and Liu, Zhaoyi and Wu, Yanru and Chen, Caixi and Liu, Benlin and Huang, Yue and Wan, Yao and Zhou, Pan and others},
journal={arXiv preprint arXiv:2411.17188},
year={2024}
}